Excel。AGGREGATE関数は、19種類の集計方法で小計を算出します 配列形式
<関数辞典:AGGREGATE関数>
AGGREGATE関数
読み方: アグリゲイト
分類: 数学/三角
AGGREGATE(集計方法,オプション,配列,[順位])

19種類の集計方法で小計を算出します 配列形式
AGGREGATE関数
読み方: アグリゲイト
分類: 数学/三角
AGGREGATE(集計方法,オプション,配列,[順位])
19種類の集計方法で小計を算出します 配列形式
Accessでテーブルからクロス集計クエリを作るには、クエリウィザードをつかうことで手早く作ることができます。

Excelのピボットテーブルには、「0(ゼロ)」で表示する方法は、ありますが、Accessには、そのような機能はありません。
そこで、Accessのクエリでは、演算フィールドをつかって「0(ゼロ)」を表示します。
では、デザインビューにして演算フィールドを設定していきます。


そして、忘れてはいけないのは、集計方法を「合計」から「演算」に変更します。
Sum関数を使うことで、「演算」に変更しないとエラーメッセージが表示されてしまいます。
では、実行して確認してみましょう。

演算フィールドを説明します。
Nz関数は、フィールドがヌル値のときに、代わりに値を代入することができる関数です。
Excelにはありません。Nz関数を使うことで、ヌル値のセルが対象で処理をしてくれます。
そのため、IIf関数のようなイメージを持たなくても大丈夫です。
その引数に、Sum関数を使います。
集計関数のSumをつかうことで、該当するデータの合算値を算出することができます。
この結果がヌル値だったら、「0(ゼロ)」で置換するように設定することで、「0(ゼロ)」を表示することができました。
ただ、よく見ると、数値が左揃えになってしまいました。
これは、数値型ではなく、文字型に変わってしまったためです。
データ型を数値型に戻す必要がありますので、演算フィールドをさらに加筆修正していきます。
デザインビューに変更します。
金額: CLng(Nz(Sum([売上高]),0))
実行して確認してみましょう。

CLng関数は、文字型(テキスト型)のデータを数値型に変換することができる関数です。
また、CLng関数は、整数の時だけに使用することができる関数です。
このように、単純に「0(ゼロ)」を表示したいだけだったのですが、色々修正する必要があります。
Accessでは、Excel以上に簡単に思えることも、ちょっと手間がかかるかもしれませんね。
やりたいことは簡単でも、どうやったら算出できるのかというケースは、結構あります。
例えば、6色あって、そのうち2色の組み合わせは、何通りあるのかを知りたい場合、目視とか、根性とかでは、時間ばかりかかって、シャレになりません。

赤と黄色という2色の組み合わせの数を知りたいので、B2には「2」と設定します。
B4に組み合わせ数を算出したいので、COMBIN関数の数式を設定します。
B4の数式は、
=COMBIN(B1,B2)
算出結果は、「15」という結果です。
つまり、2色の組み合わせのパターンは、15通りあるということがわかりましたね。
では、COMBIN関数の基本情報を確認しておきましょう。
COMBIN関数の読み方は「コンビネーション」です。
所属は、「数学/三角」です。
COMBIN関数の引数は、
COMBIN(総数,抜き取り数)
AGGREGATE関数
読み方: アグリゲイト
分類: 数学/三角
AGGREGATE(集計方法,オプション,範囲1,[範囲2],…)

19種類の集計方法で小計を算出します セル範囲形式
Excelには、便利な機能がたくさんあります。
例えば、条件付き書式をつかえば、視覚的にデータの特徴を知ることも出来ます。
また、オートフィルターを使えば、簡単に希望する条件でデータを抽出することも出来ます。
ただ、この2つを組み合わせて使うと、思ったように機能してくれません。
次の表を使って説明します。

F2:F6を範囲選択して、ホームタブの条件付き書式にある「上位/下位ルール」の「上位10%項目」をクリックします。


書式を設定したらOKボタンをクリックします。
設定後に、英語の点数が70点以上のデータをオートフィルターで抽出したら、どうなるか、確認してみましょう。
英語の見出しにある、オートフィルターの数値フィルターにある「指定の値以上」をクリックします。



要するに、表示されているデータに対して、条件付き書式が対応しているわけではないのです。
このように、データが非表示になっても対応させるには、設定されている条件付き書式の機能では対応できないので、新しいルールを作る必要があります。
つまり、数式をつかった条件付き書式をつくるわけです。
非表示のデータとなれば、SUBTOTAL関数やAGGREGATE関数の登場ですね。
オートフィルターをクリアして、F列の条件付き書式も削除したら、F2:F6を範囲選択します。


=F2=AGGREGATE(4,5,F2:F6)
書式を設定したら、OKボタンをクリックします。

では、オートフィルターをつかって、同じ条件で抽出してみます。

数式で設定した、
=F2=AGGREGATE(4,5,F2:F6) のAGGREGATE関数も確認しておきましょう。

4番は、MAX。最大値を算出することができます。
次の引数は、オプション。

5番の「非表示の行を無視します」を選ぶことで、オートフィルターにも対応してくれるようになります。
COULUMN関数は、列番号を算出してくれますが、範囲選択した範囲の列数。
あるいは、テーブルのフィールド数を知りたい時には、COLUMN関数を終点から始点を減算するとなると、結構面倒です。
このような時には、COLUMNS関数を使えば、簡単に算出することができます。

G2には、
=COLUMN(B2:D9)
という数式を設定しました。スピル機能によって、G2:I2まで算出されましたが、あくまでも、B列なので、2からD列なので、4までの列番号を算出されているだけです。
ところが、COLUMNS関数をつかった、G3の数式は、
=COLUMNS(B2:D9)
と先程のCOLUMN関数と同じ範囲を設定したところ、「3」と範囲選択されている列数を算出してくれました。
このように、表やテーブルが大きい場合、フィールド数がいくつなのかを把握することが簡単にできます。
Excel VBAで列方向で繰り返し処理をする場合などに重宝しそうですね。
最後に、COLUMNS関数の基本情報を確認しておきましょう。
COLUMNS関数の読み方は「カラムズ」です。
所属は、「検索/行列」です。
COLUMNS関数の引数は、
COLUMNS([配列])
Excelには、似ている関数というのがチラホラあります。
算出結果が今回のように異なることもありますので、色々試してみるといいかもしれませんね。
ADDRESS関数
読み方: アドレス
分類: 検索/行列
ADDRESS(行番号,列番号,[参照の種類],[参照形式],[シート名])

行番号・列番号をセル参照に変換する
大量なデータを読み込んだら、列幅が狭くて「#」で表示されているとします。
一目でわかるぐらいのデータ量ならば、列幅を広げないといけないと判断できますが、データ量が増えるとそういうわけにもいきません。
また、印刷することも考えると、セル内余白というか、列幅の自動調整では、印刷時見切れてしまう恐れがあります。
このようなことから、自動調整した列幅を少し広げた状態にしたいわけです。
列幅をまとめて自動調整することは、簡単ですが、少し列幅を広げる作業は、面倒な作業だといえます。
そこで、Excel VBAでマクロをつくって対応してみましょう。
次のようなデータを用意しました。

Sub 列幅調整()
Dim i As Long
For i = 1 To Range("a1").CurrentRegion.Columns.Count
Range("a1").CurrentRegion.Columns(i).EntireColumn.AutoFit
Range("a1").CurrentRegion.Columns(i).ColumnWidth = Range("a1").CurrentRegion.Columns(i).ColumnWidth + 2
Next
End Sub
まずは、実行してみましょう。

では、プログラム文を確認しておきましょう。
まずは、変数宣言ですね。
Dim i As Long
プログラム文の処理本体が、For To Next文です。
For i = 1 To Range("a1").CurrentRegion.Columns.Count
Range("a1").CurrentRegion.Columns(i).EntireColumn.AutoFit
Range("a1").CurrentRegion.Columns(i).ColumnWidth = Range("a1").CurrentRegion.Columns(i).ColumnWidth + 2
Next
説明の為、With文をつかわないでいます。
For文なので、繰り返し処理をさせています。
何回繰り返すのかというと、
Range("a1").CurrentRegion.Columns.Count
A1を起点とした連続したセル(CurrentRegion)。
つまり表の列数(Columns.Count)を算出しています。
これで、この表が何列の表なのかがわかりました。
その回数まで繰り返し処理を行うわけです。
Range("a1").CurrentRegion.Columns(i).EntireColumn.AutoFit
Columns(i).EntireColumn.AutoFit は、列幅を自動調整しています。(AutoFit)
自動調整することで「#」で見えなくなっているデータも見えるようになります。
Range("a1").CurrentRegion.Columns(i).ColumnWidth = Range("a1").CurrentRegion.Columns(i).ColumnWidth + 2
Columns(i).ColumnWidthは、「Width」なので、列幅ですね。
この列幅を「ColumnWidth + 2」。つまり、2文字分広げるようにします。
「+2」は目分量なので、増やしたい時には、数値を増減させます。
これで、セル内余白というか、印刷時に見切れる可能性を抑制できます。
プログラム文も多くないので、事前につくっておくといいかもしれませんね。
なお、「Range("a1").CurrentRegion」が何度も登場します。
わかりにくいのと、入力が面倒なので、With文をつかうと、よりシンプルにすることができます。
下記は、With文をつかった、ブログラム文です。
Sub 列幅調整with文()
Dim i As Long
With Range("a1").CurrentRegion
For i = 1 To .Columns.Count
.Columns(i).EntireColumn.AutoFit
.Columns(i).ColumnWidth = .Columns(i).ColumnWidth + 2
Next
End With
End Sub
結構シンプルな印象にかわりましたね。
Facebookページで【書いてみた】Excelの豆知識(Trivia)です。

1月17日
Excel。eomonth関数は指定した日付の何か月後の末日を算出関数です。
1月18日
Excel。weekday関数は日付の曜日を番号として算出関数です。
1月19日
Excel。weeknum関数はその年の何週目にあたるか算出関数です。
1月20日
Excel。workday関数は土日・休日・祝日を除いた○日後の日付を算出関数です。
1月21日
Excel。networkdays関数は土日・休日・祝日を除いた日数を算出関数です。
1月22日
Excel。datedif関数は満年齢などの指定した期間を算出関数です。
1月23日
Excel。phonetic関数はふりがな抽出関数です。
ACOTH関数
読み方: ハイパーポリック アーク コタンジェント
分類: 数学/三角
ACOTH(数値)

数値の双曲線逆余接を算出します
アンケート結果やサンプルデータなど、集計する時に「平均値」や「中央値」だけでは、全体像が把握できません。
次のデータで説明します。
説明の為極端な数値にしております。
データも少ないです。

サンプルAとサンプルB。
ともに、平均値は、「1.9」と算出されています。
中央値を算出したとしても、サンプルAの中央値は「1」。
サンプルBの中央値は「2」と算出されて、差はありません。
これらの数値からだけだと、サンプルAとサンプルBには差がないように感じてしまう恐れがあります。
平均値や中央値では、データの全体像がみえてこないわけです。
どのようにしたらデータの全体像を把握することができるのか、案として、データの分布状況を把握するだけでも、全体像が見えてきます。
ヒストグラムをつくってもいいのですが、手間暇を考えると、関数をつかってみる方法もあります。
Excelでは、分布の形を知るための歪度(わいど)を算出する関数。
SKEW関数。
尖度(せんど)を算出する関数。
KURT関数が用意されています。
使い方はとてもシンプルなので、日頃から使っている資料にプラスしてみるのもいいかもしれませんね。
まずは、SKEW関数・KURT関数をつかって、歪度と尖度を算出してみましょう。

=SKEW(B2:B11)
G2の数式は、
=SKEW(C2:C11)
F3の数式は、
=KURT(B2:B11)
G3の数式は、
=KURT(C2:C11)
どの数式の引数も、該当データ範囲を選択しただけです。
これだけの数式ですが、データの全体像を把握することができます。
ところ、そもそも、歪度・尖度とはなんなのかというと、歪度は、データの分布が平均値を中心としてどちらに偏っているかという値です。
尖度は、データの分布が平均値の近くにまとまっているかという値です。
では、算出結果は何を意味しているのか、歪度からみていきましょう。
SKEW関数の算出結果が「0(ゼロ)」に近ければ、平均値を中心として、データは、左右対称の分布状況ということがわかります。
また、算出結果が、「正数」ならば、平均値よりも左寄り。
「負数」ならば右寄りということがわかります。
サンプルAの歪度は、「3.16227766」。
サンプルBの歪度は、「0.165950431」なので、サンプルBの方が平均値を中心として、少し左側に寄っているデータということがわかります。
サンプルAは、サンプルBと比べて、左側に大きく寄っていることがわかります。
つづいて尖度を見てみましょう。
KURT関数の算出結果が「0(ゼロ)」に近ければ「正規分布」に近くなります。
算出結果が「正数」ならば、正規分布からみて、先端が尖った分布ということがわかり、「負数」ならば、正規分布からみて、頂点が低い、平べったい分布であることがわかります。
サンプルAは「10」。
サンプルBは「-0.733622895」サンプルAは極端なデータで、10件中9件が平均値に違いわけです。
サンプルAのほうが、サンプルBに比べて平均値の近くに集まっていることがわかります。
今回のように、平均値だけに頼っていると、判断が難しいケースもありますので、他の数値を算出して、全体像を確認できるようにすると、今までと違ったものが、資料から見えてくるかもしれませんね。
途中計算をつかって、最終的な算出結果を求めることは、長い数式よりも、シンプルでわかりやすいこともあり、よくつかいます。
例えば次のような表。
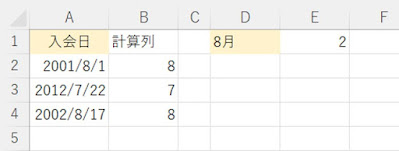
入会日から、一発で、算出するのではなく、B列にMONTH関数をつかって、月を算出し、その結果から、COUNTIF関数をつかい、E1に「2」と算出してあります。
E1の数式は、
=COUNTIF(B2:B4,8)
この表を印刷するとしたら、当然、B列も印刷されてしまいます。
そこで、B列を非表示にしますが、非表示にすると、その分が狭くなり、印刷時の見栄えがおかしくなります。
出来れば、B列を非表示にしないで、途中の算出結果を非表示にしたいわけです。
当たり前ですが、B列の算出結果そのものを削除したら、E1は算出されません。
そこで、表示形式をつかうことで、非表示にすることができます。
B1:B4を範囲選択します。
セルの書式設定ダイアログボックスを表示します。

表示形式の「ユーザー定義」をクリックして、「;;;(セミコロン×3)」と設定します。
OKボタンをクリックして、確認してみましょう。

このように、B列を非表示にすることなく、データのみを非表示にすることができました。
「;;;(セミコロン×3)」を覚えておくと、色々重宝しますので、機会がありましたら、使ってみるといいかもしれませんね。
ところで、なぜ、「;;;(セミコロン×3)」で非表示になるのかというと、表示形式のルールがあって、「正数;負数;ゼロ;文字」という順番になっています。
それぞれを「空白」にすることで、どのような文字や数値でも、「表示しない」ようにすることができるわけです。それで、それぞれの境目にある「;(セミコロン)」のみが残ったのが、「;;;(セミコロン×3)」というわけです。
ACOT関数
読み方: アーク コタンジェント

分類: 数学/三角
ACOT(数値)
数値の逆余接を算出します
条件付き書式をつかうことで、視覚的に資料をわかりやすくすることができます。
最初から用意されているものでも十分ですが、行全体にも反映させたい場合は、アレンジしないとできません。
今回は、上位3件のデータの行全体を塗りつぶししたい場合でみてみましょう。


やりたいことは、上位3件。
つまり、1位~3位のデータがわかればいいわけです。
そこで、使う関数は、LARGE関数です。
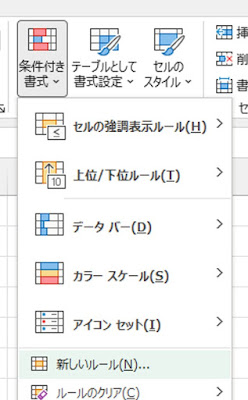
A2:F6を範囲選択して、ホームタブの条件付き書式にある「新しいルール」をクリックします。

「数式を使用して、書式設定するセルを決定」をクリックして、「次の数式を満たす場合に値を書式設定」のボックスに、次の数式を設定します。
=$F2>=LARGE($F$2:$F$6,3)
あとは、書式ボタンをクリックして、セルの色を設定したら、OKボタンをクリックして設定完了です。
これで、行全体に塗りつぶしを行うことができました。
数式も確認しておきましょう。
「$F2」のように、列固定の複合参照にすることで、行全体を対象とすることができます。
「LARGE($F$2:$F$6,3)」で、上位3番目の値を算出できます。
その値以上ならば、上位1位~3位に該当します。
逆に、下位の場合には、「SMALL関数」をつかえば、同じように設定することができます。
ところで、なぜ、LARGE関数をつかうのかというと、MAX関数は、最上位のデータしか判別できません。
最上位(1位)以外の上位の値を算出するには、LARGE関数を使う必要があります。
RANK.EQ関数という方法もありますが、一度順位を算出させたあと、3以下のデータなのか判断させる数式で条件を設定する必要があるので、LARGE関数よりも、作業量が増えてしまいます。
手早く行う点からみても、LARGE関数をつかうといいですね。
Facebookページで【書いてみた】Excelの豆知識(Trivia)です。

1月10日
Excel。month関数は月を抽出する関数です。
1月11日
Excel。day関数は日を抽出する関数です。
1月12日
Excel。time関数は数値から時刻を算出関数です。
1月13日
Excel。hour関数は時間を抽出する関数です。
1月14日
Excel。minute関数は分を抽出する関数です。
1月15日
Excel。second関数は秒を抽出する関数です。
1月16日
Excel。edate関数は指定した日付の何か月後を算出関数です。
Excelには、簡単そうに見えて、意外とどうやったらいいのか。
行うとしても面倒な処理になることが結構あります。
次のようなケースもそのひとつです。

横方向を縦方向に貼り付けるコピーがあるのですが、今回は、セル参照させたいわけです。
横方向を縦方向にするだけなのですが、結構大変です。
セル参照の数式をオートフィルで下方向にコピーすればいいと考えますが、うまくいきません。

=B7という数式を設定したセル参照をつくり、オートフィルで数式をコピーしても、列方向にコピーしたのではなく、行方向にコピーしたので、
H4の数式は、
=B9となってしまっています。
本当ならば、D7としたいわけです。
オートフィルで数式をコピーするときには、横方向なら横方向、縦方向なら縦方向にコピーするので、今回のように、横方向を縦方向では、オートフィルで数式をコピーすることができないわけです。
当然、一つずつ、セル参照を設定するのは、大変というか、データ量があれば、無理です。
また、この程度のことで、わざわざ、Excel VBAでマクロをつくるというのも、面倒です。
そこで、登場するのが「OFFSET関数」です。
OFFSET関数は、セルから指定した行・列方向のデータを参照することができます。
まずは、動きを確認したいので、OFFSET関数のみで作り直してみます。

H2には、
=OFFSET($B$7,0,0)
最初の引数は、起点となるセル番地なので、$B$7。
オートフィルで数式をコピーすることを前提としているので、絶対参照も設定しておきます。
2つ目の引数は、行数。
起点から何行のところという意味ですが、今回は、列方向のみで、行方向(横方向)は変動しないので、「0(ゼロ)」
3つ目の引数が、列数。
ここがポイントになるわけですね。
1列ずつスライドするので、「+1」ずつしたいわけです。
H4の数式は、
=OFFSET($B$7,0,2)
オートフィルで数式を縦方向にコピーしても、3つ目の引数は、「+1」されません。
そこで、アイディアが必要となるわけです。
なお、残りの引数は、今回関係ないので、省略します。
さて、3つ目の引数の列数に、ROW関数をつかうことで、「+1」させることができます。
H2の数式を次のように変更します。
=OFFSET($B$7,0,ROW(A1)-1)
ROW関数は、行番号を算出してくれる関数です。
ROW(A1)とすれば、「1」を算出してくれますので、その値から「-1」すれば、「0(ゼロ)」になります。
H4の数式は、
=OFFSET($B$7,0,ROW(A3)-1)
と「A1」が「A3」に変わっています。
ROW(A3)なので、「3」。マイナス1とすれば、「2」を算出してくれます。
よって、オートフィルで数式をコピーすることで、横方向のデータを縦方向でセル参照することができました。
OFFSET関数を知ることで、日頃面倒な作業も、改善できるかもしれませんので、OFFSET関数が使えないか、チェックするというのもいいかもしれませんね。
列番号を算出するには、「COLUMN関数」をつかうことで、確認することができます。
COLUMN関数の読み方は「カラム」です。
所属は、「検索/行列」です。
COLUMN関数の引数は、
COLUMN([参照])
COLUMN関数や行番号を算出できるROW関数とも、あまり単独で使用することはありません。
多く使うのは、Excel VBAで、列方向に移動させて処理するときなどに使用します。
あとは、VLOOKUP関数の列番号に、COLUMN関数をつかうことで、VLOOKUP関数を列方向にオートフィルで数式をコピーするとき重宝する関数です。

B4には、E3:G6の範囲のデータから、商品名を検索抽出するために、VLOOKUP関数をつかっていますが、C列の単価にも、オートフィルで数式をコピーする前提で数式をつくるとしたら、列番号がネックになります。
列番号を商品名は、「2」。単価は「3」と設定修正する必要があります。
修正箇所が多くなると、修正自体は簡単でも面倒になります。
そこで、B4に設定するVLOOKUP関数を次のようにします。
=VLOOKUP($A$4,$E$4:$G$6,COLUMN(B1),FALSE)
3番目の引数の「列番号」のところに、COLUMN関数をつかうことで、列番号を修正しないですむようになります。
COLUMN関数は、主役になる関数ではないかもしれませんが、ちょっとしたところで、活躍する関数なので、用途に合わせ、組み込んでみると、重宝するかもしれませんね。
ACOSH関数
読み方: ハイパーポリック アークコサイン
分類: 数学/三角
ACOSH(数値)

数値の双曲線逆余弦を算出します
フリガナを使った抽出で、ちょこちょこ問題になるのが、フリガナ濁点問題です。
例えば、「中田さん」。
ナカタさんなのかナカダさんなのかという「タ・ダ」の違いのことです。
抽出するときに、氏名の漢字で抽出すればいいのでと思っても、漢字は漢字で「中田さん」なのか「仲田さん」なのかというケースも考えられます。

OR条件を使う方法も考えることもできますが、Like演算子で「[]」を組み合わせることで、抽出するクエリをつくることができます。
それでは、クエリデザインをつかって、クエリをつくっていきましょう。

抽出条件に次のような条件を設定します。
Like "ナカ[タダ]*"
まずは実行して確認してみましょう。
ご覧のように、「タ」「ダ」のデータのみが抽出することができました。

では、抽出条件を確認しておきましょう。
Like "ナカ[タダ]*"
Like演算子は、あいまい検索を行う時につかう、演算子です。
最後の「*(アスタリスク)」は、ワイルドカードですね。
ワイルドカードを検索文字の最後尾につけることで、検索文字で「始まる」という条件になります。
そして、今回のポイントは「[ ]」の大カッコ(ブラケット)です。
この記号をつかうことで、文字の種類をして、その中の文字と合致するかどうかという判定を行ってくれます。
つまり、今回は、「[ ]」の中に、タとダが入力されていますので、「ナカタ」と「ナカダ」のそれぞれで始まる文字を抽出するという条件がつくれたわけです。
今回のようにフリガナ濁点問題に限らず、一文字だけ違う条件などの場合は、Like演算子と「[ ]」大カッコを組み合わせて抽出条件をつくってみるという方法もあります。
Facebookページで【書いてみた】Excelの豆知識(Trivia)です。

1月3日
Excel。isna関数は#N/Aのエラー判定関数です。
1月4日
Excel。error.type関数は数式の結果のエラー判定関数です。
1月5日
Excel。now関数は日付と時刻関数です。
1月6日
Excel。today関数は日付と時刻関数です。
1月7日
Excel。days関数は日数計算関数です。
1月8日
Excel。date関数は数値から日付を算出関数です。
1月9日
Excel。year関数は年を抽出する関数です。
Excelで並べ替えをする場合、昇順降順のボタンや、並べ替えボタン。
あるいは、オートフィルターをつかっての並べ替えなど、様々な方法があります。
並べ替えをしたデータを別シートに転記したい場合、どの方法でも、元データを並べ替えしてからでないと、転記することはできません。
どのようにしたら、手早くおこなうことができるのでしょうか?
例えば、次のデータ。

今回のデータは、連番のNOフィールドがあるので、並べ替えをして、処理をした後でも、元に戻せますが、NOフィールドのようなデータが無い場合は、並べ替えてしまうと、元に戻すことが難しいわけです。
なので、今回紹介する方法を知っていると手早く処理を行うことができます。
その方法とは、SORT関数をつかいます。
準備として、転機先のシートに見出し行をコピーしておきます。

A2に設定する数式は、
=SORT(成績シート!A2:F6,6,-1,FALSE)
数式を確定すると、スピル機能によって、自動的に、数式がコピーされるので、合計フィールドが降順のデータで表示されていることが確認できます。

最初の引数は、配列。
まぁ、対象範囲ですね。
今回は、データがあるシートの、A2:F6が対象です。
2番目の引数は、
並べ替えインデックス。
並べ替えを行いたい列番号です。
今回は、合計フィールドなので、配列(範囲)の左側から、「6」番目にあるので「6」。
3番目の引数は、並べ替え順序。
昇順なのか降順なのかを設定することが出来ます。
昇順なら「1」。降順なら「-1」。
最後の引数は、
並べ替え基準。
列で並べ替えをするのか、行で並べ替えをするのかを設定することができます。
列ならば「TRUE」、行ならば「FALSE」と設定します。
引数の設定もわかりやすい関数ですので、色々試してみるといいかもしれませんね。