Excel。条件を満たすレコードの数値の個数を算出するのが、DCOUNT関数です。
<関数辞典:DCOUNT関数>
DCOUNT関数
読み方: ディーカウント
分類: データベース

DCOUNT(データベース,フィールド,条件)
条件を満たすレコードの数値の個数を算出します
DCOUNT関数
読み方: ディーカウント
分類: データベース
DCOUNT(データベース,フィールド,条件)
条件を満たすレコードの数値の個数を算出します
1位の得点なら「A」。
2位が「B」で3位が「C」として、それ以外は空白とする場合、次の表のように、手早く算出するにはどのようにしたらいいのでしょうか。

そのため、処理が面倒になりがちです。
そこで、SWITCH関数とRANK.EQ関数を組み合わせることで、手早く算出することができます。
D2に設定した数式は、
=SWITCH(RANK.EQ(C2,$C$2:$C$7,0),1,"A",2,"B",3,"C","")
設定した数式をオートフィルでコピーしています。
これで、1位はAとして、該当しない場合は、空白というように設定することができました。
SWITCH関数の引数を確認しておきましょう。
SWITCH関数は、「多分岐処理」を行うことができる関数です。
このSWITCH関数の最初の引数は、「式」で、この式の結果をこのあとの引数で判別し設定していきます。
やりたい処理は、1位から3位を算出したいわけです。
そこで、順位を算出するならば「RANK.EQ関数」をつかうことで算出することができます。
RANK.EQ関数をつかえば、仮に1位が複数あった場合でも対応してくれます。
この結果をもとにして、2つ目以降の引数が対応していきます。
2つ目の引数は、「値1」です。
最初の引数の結果が「1」の場合ということなので引数には、「1」と設定します。
3つ目の引数は、「結果1」です。2つ目の引数と合致した場合に、結果1で設定した処理をするわけです。
2つ目の引数の結果「1」だったら、「A」と表示したいので、結果1に設定する値は「A」となるわけです。
あとは、2と3を繰り返し設定します。
そして、1位~3位以外は、空白にしたいので、最後の引数の値に「””(ダブルコーテーション×2)」を設定すれば、数式は完成します。
SWITCH関数は、色々つかってみると、日頃使っている数式がより、わかりやすくなるかもしれませんね。
今までは、IF関数にIF関数を重ねたネストで多分岐処理に対応していました。
そして、登場したIFS関数で多分岐処理を設定するのが、より手早く設定できるようになりました。
ただ、条件を設定するときに、「それ以外」をどうしたらいいのかが、わかりにくいので、確認しておきましょう。
次の表を用意しました。

60より大きければ「B」。
それ以外は「C」とします。
C2の数式は、
=IFS(B2:B7>90,"A",B2:B7>60,"B",TRUE,"C")
と設定しています。
なお、スピル機能によって、オートフィルで数式をコピーする必要はありません。
それでは、引数を確認しておきます。
1番目の引数は、論理式1。
条件を設定しますので、「B2:B7>90」と、B2:B7とフィールドで範囲選択を指定することで、スピル機能をつかうことができます。
2番目の引数が、論理式1が真の場合の結果を表示させます。
このあとは、これを繰り返すことで、多分岐処理を設定できます。
そして、「TRUE」を設定することで、それ以外の場合の条件を設定することができます。
また、Excelでは、TRUEを「1」としていますので、
=IFS(B2:B7>90,"A",B2:B7>60,"B",1,"C")
としても、対応してくれます。
ただし、この「1」はなんなのか、わかりにくいので、「TRUE」とするようにした方がいいように思えます。
Facebookページに書いた、Excelの豆知識(Trivia)です。

2月26日
Excel。
RIGHT関数
読み方は、ライトで、文字列の右端から文字を取り出す
2月27日
Excel。
RIGHTB関数
読み方は、ライトビーで、文字列の右端から指定のバイト数を返す
2月28日
Excel。
ROMAN関数
読み方は、ローマンで、アラビア数字をローマ数字に変換します。
3月1日
Excel。
ROUND関数
読み方は、ラウンドで、指定桁数で四捨五入します。
3月2日
Excel。
ROUNDDOWN関数
読み方は、ラウンドダウンで、指定桁数で切り捨てる
3月3日
Excel。
ROUNDUP関数
読み方は、ラウンドアップで、指定桁数で切り上げる
3月4日
Excel。
ROW関数
読み方は、ロウで、セルの行番号を算出します。
日付だけではなく、文字も含まれている列から、日付が入力されているセルかどうかを判断させるには、どうしたらいいのでしょうか。
次の表を用意しました。

D列には、「日付だったら」という条件で判断したいので、IF関数をつかうことで、「済」という文字を表示することができそうです。
ただ、どのようにしたら、日付と文字をわけて判断することができるのでしょうか。
D2に次の数式を作ります。
=IF(ISNUMBER(C2),"済","")
あとは、オートフィルで数式をコピーします。
これで、提出日に日付が入力されているものだけに「済」という文字を表示することができました。
この数式を説明します。
日付の期間がわかっているならば、この期間内なのかを判断させればよいのですが、今回は期間がわかりません。
また、日付がシリアル値であることを考えて「>=1」というように1以上すると、日付は確かに判断できるかもしれませんが、文字もJISコードで判断されますから、結局日付も文字も区別することができません。
そこで、ISNUMBER関数というのがあります。
このISNUMBER関数は、数値かどうかを判断することができる関数です。
ISNUMBER関数が数値かどうかを判断できるならば、この関数だけでいいように思えますが、このISNUMBER関数は、TRUEかFALSEという形で結果を算出します。
そのため、IF関数をつかうことで、結果をわかりやすくすることができます。
紹介したISNUMBER関数をはじめとする「IS系」関数は色々ありますので、意外とつかえるものが見つかるかもしれませんので、調べてみるといいかもしれませんね。
DB関数
読み方: ディービー
読み方: ディクライニングバランス
分類: 財務

DB(取得価額,残存価額,耐用年数,期,[月])
減価償却を旧定率法で算出します
fixed-Declining Balance methodの略
月末は、月ごとで、30日だったり31日だったりします。
月末日だけの表を作りたい場合、どのようにしたら、手早く作成することができるのでしょうか。
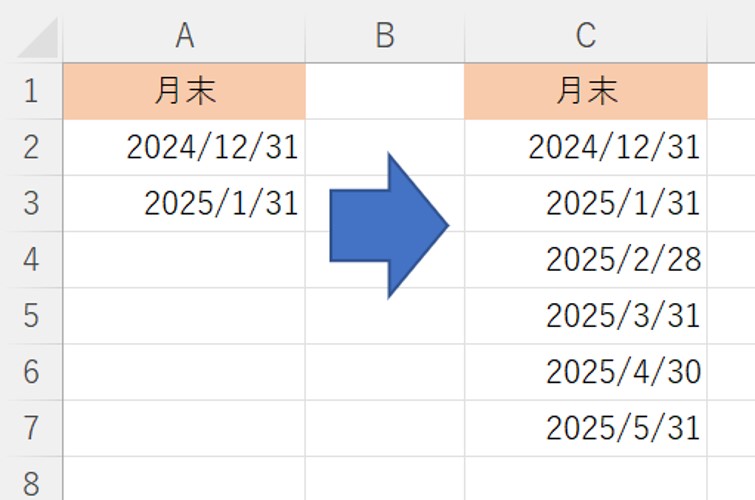
月末を算出する関数など、使わなくて大丈夫です。
ポイントは、A2とA3のように、二か月分の月末日を入力します。

A2とA3の日数を数えて、次のセルに加算するのではなく、A2とA3が月末であるということを認識するようで、オートフィルで連続コピーすると、翌月の月末日を入力してくれます。
テーブル機能を表に追加すれば、表のデザインを、横縞模様を選べば、並べ替えをしても横縞模様で設定されます。
では、通常の帳票や表の場合、どうしたら効率よく、縞模様することができるのでしょうか。

一行おきに塗りつぶすということで、条件付き書式をつかうと対応することができます。
では、条件付き書式を設定していきます。
A2:C11を範囲選択します。
ホームタブの条件付き書式にある「新しいルール」をクリックします。


次の数式を満たす場合に値を書式設定のボックスに、次の数式を設定します。
=mod(row(),2)
あとは、書式ボタンをクリックして、書式を設定します。
新しいルールダイアログボックスに戻ってきたらOKボタンをクリックします。
これで、横縞模様を設定することができました。
売上高を降順にしてみます。

設定した数式を説明します。
=mod(row(),2)
最初のMOD関数は、除算した余りを算出することができる関数です。
何を除算するのかというと、それがROW関数です。
MOD関数の最初の引数は、ROW関数で、そのセルの行番号を算出することができる関数です。
A3は、3行目なので、「3」を算出するわけです。
今回は、1行おきなので、2で除算するので、引数の2つ目は、「2」と設定します。
さて、
行番号を2で除算した余りが、「1」と「0」が算出されるわけですね。
設定した数式には「=1」とか「=0」とかありませんが、塗り分けされています。
これは、1ならば、Excelでは、1を「TRUE」としています。
すなわち、この数式の条件は成立しているということを意味することになるので、書式が反映されるというわけです。
余りがない場合は0なので、Excelでは、0を「FALSE」としています。
FALSEですから、この数式の条件は合致していないということを意味していますので、そのままで、塗りつぶしはされないというわけです。
条件付き書式は、数式を設定することで、様々な表現をすることができます。
VLOOUP関数をつかった数式の算出結果で「#N/A(ノーアサイン)」というエラーが表示されることがあります。
どのようにしたら、エラーを表示させないで済むのでしょうか。

=VLOOKUP(A2,$A$5:$B$7,2,FALSE)
と設定してあります。
B2に表示されている「#N/A」の原因は、検索するコードが、範囲にないので探せないというエラーです。
今回の場合は、A2に「A04」と入力されていますが、A5:A7には、「A04」はありません。
そのため、抽出することができないため、「#N/A」が表示されてしまったというわけです。
そこで、エラーが発生した時に、どのようにするのか処理できるIFERROR関数をつかうことで、「#N/A」を表示しないようにすることができます。
B2の式を次のように修正します。
=IFERROR(VLOOKUP(A2,$A$5:$B$7,2,FALSE),"")

DAYS360関数
読み方: デイズ360
分類: 日付時刻

DAYS360(開始日,終了日,[方式])
1年を360日として2つの日付の間の日数を算出します
リストから該当するデータを抽出することができる、VLOOKUP関数。
このリストの選択先が複数ある場合、どのようにしたら、手早く抽出することができるのでしょうか。

C2の数式は、
=VLOOKUP(B2,INDIRECT(A2),2,FALSE)
どのような仕組みなのか説明していきます。
A2に、「校庭」「体育館」を入力します。会場番号を入力すると、「校庭」の3番である「陸上」が抽出されるという仕組みです。
この数式を作る場合には、事前に引数の範囲に該当するところに、名前の定義を使って「名前」を設定します。
A5:B7には、「校庭」という名前を設定してあります。
D5:E7には、「体育館」という名前を設定してあります。
あとは、VLOOKUP関数を設定していきます。
最初の引数の検索値には、「B2」を設定します。
2つ目の引数の範囲ですが、ここが2か所あるわけです。
そこで、名前の定義を指定してあげれば、その範囲の検索値からデータを抽出してくれるわけですが、検索する範囲を変更するたびに、数式を変更するのは大変です。
そこで、INDIRECT関数をつかうことで、範囲に、名前の定義で設定した名前を指定することができます。
なので2つ目の引数は、「INDIRECT(A2)」と設定します。
これで、A2に、「校庭」と入力されれば、名前の定義で設定した「校庭」の範囲を選んでくれます。
3つ目の引数の列番号には、「2」。
2つ目の引数で選択した範囲の左から2列目に、抽出したい列がありますので、「2」と設定するわけですね。
最後の引数の検索方法は、「FALSE」。
完全一致で抽出しますので、「FALSE」または、「0」と設定します。
Excelでは、FALSE=0なので、「0」と設定しても大丈夫です。
これで、A2の値を校庭・体育館と切り替えれば、それぞれの範囲から該当するデータを抽出することができます。
このように、VLOOKUP関数は、アイディアを追加することで、様々なビジネスシーンでさらに使えるようになりますので、色々試してみるといいかもしれませんね。
なお、あとプラスするとしたら、A列に入力規則のリストをつかうと、「校庭」「体育館」を選択して選ぶことができますので、おすすめの機能ですね。
Facebookページに書いた、Excelの豆知識(Trivia)です。

2月19日
Excel。
RANK.AVG関数
読み方は、ランク・アベレージで、同順位を平均順位で算出する
2月20日
Excel。
RANK.EQ関数
読み方は、ランク・イコールで、数値の大小で順位を算出する
2月21日
Excel。
RATE関数
読み方は、レートで、元利均等返済における利率を算出する
2月22日
Excel。
RECEIVED関数
読み方は、レシーブドで、割引債の償還価格を算出します。
2月23日
Excel。
REPLACE関数
読み方は、リプレイスで、指定した文字数の文字列を置換する
2月24日
Excel。
REPLACEB関数
読み方は、リプレイズビーで、指定した位置からバイト数分の文字列を置換する
2月25日
Excel。
REPT関数
読み方は、リピートで、文字列を指定回数だけ繰り返して表示する
DAYS関数
読み方: デイズ
分類: 日付時刻

DAYS(終了日,開始日)
2つの日付の間の日数を算出する
1か月後の日付を算出としたら、Excelでは、EDATE関数をつかえば、手早く算出することができます。
では、Accessの場合、どのようしたらいいのでしょうか。
Accessには、EDATE関数は用意されていませんが、DateAdd関数というのが用意されています。
このDateAdd関数をつかった演算フィールドで1か月後などの日付を手早く算出することができます。
用意したテーブルです。


設定した演算フィールドは、
経費提出期限: DateAdd("m",1,[日付])
実行して結果を確認します。

では、DataAdd関数を確認しておきます。
最初の引数は、「単位」です。「”m”」とすることで「月」とすることができます。
単位を「”yyyy”」とすることで、何年後と算出することができます。
2つ目の引数は、1か月後なので「1」と設定します。
「6」とすれば、半年後になるというわけです。
3つ目の引数は、対象となるフィールド名です。
今回は、日付の1か月後なので「[日付]」と設定します。
Accessには、ExcelのEDATE関数はありませんが、EDATE関数よりも使い勝手がいい、DateAdd関数というのが用意されています。
ホームタブにある条件付き書式。その条件付き書式に「データバー」といって、数値を横棒グラフで表示してくれる機能があります。


C2に
=B2
と数式を設定したら、オートフィルで数式をコピーします。

C2:C8を範囲選択したら、ホームタブの条件付き書式にある「ルールの管理」をクリックします。


「書式ルールの編集」ダイアログボックスが表示されます。

一つ前の「条件付き書式ルールの管理」ダイアログボックスに戻りますので、OKボタンをクリックして、完成です。

セル内に表示されていますので、列幅を調整すれば、連動して長さを変えることができます。
DAY関数
読み方: デイ
分類: 日付時刻

DAY(シリアル値)
日付から日を算出する
Excelでは、平均値を算出するだけならば、ホームタブのオートSUMボタンの中にある平均をクリックするだけで、平均値を算出することができます。
ただ、そもそも、「平均値」だけでは、データ全体の状況を把握するには、ちょっと足らないわけですね。
次の表を用意しました。

=AVERAGE(B2:B6)
という数式を設定してあります。
この数式をC7にオートフィルでコピーしました。
競技1と競技2の平均値ですが、同じ「50」と算出されています。
ただ、競技1と競技2の数値をみると、競技1よりも競技2のほうが、それぞれのデータは50近くにあります。
しかし、競技1のデータには、差があるようにみえます。
データとしては、バラバラだということです。
そして、平均値は、突出した数値があると、それに引っ張られる傾向にあります。
つまり、平均値だけだと、どうしても、データの全体像がわからないわけです。
そこで、データ全体の中央の値である、「中央値」を算出するだけで、データ全体がどのようになっているのか、把握しやすくなります。
B8には、中央値を算出することができる関数。
「MEDIAN関数」をつかった数式を設定してあります。
=MEDIAN(B2:B6)
C8には、オートフィルでコピーした数式が設定してあります。
その結果、競技1の中央値は、「30」であり、競技2の中央値は「49」ということがわかりました。
見た目に近い印象の数値が算出されました。
中央値は、平均値と異なり、一部の外れた値の影響を受けにくい傾向にあります。
中央値を算出するMEDIAN関数は、比較的わかりやすいので、いつも算出している平均値と合わせて中央値も算出してみるといいかもしれませんね。
データとデータの相関(関係)が強いのか弱いのかというのを数値にしたのが、相関係数です。
この相関係数が「1」に近いと強いといわれています。
どのようなことなのか理解するには、データを「散布図」をつかって見える化してみるといいかもしれません。
次のデータを使ってみます。

B10の数式は、
=CORREL(B2:B8,C2:C8)
CORREL関数をつかうと、手早く相関係数を算出することができます。
その結果は、「1」。
このデータAとデータBをつかって、散布図をつくっていきます。
A1:B8を範囲選択します。

散布図のグラフが挿入されました。
グラフを大きく表示したいので、ラベルは削除した状態で、少しグラフを大きくしています。
縦軸・横軸ともフォントサイズを大きくしています。

これが確実といっていいレベルだということが見えます。
Y=10Xという一次方程式で表すことができます。
それでは、データBをいい加減な数値にしてみると、散布図がどうなるのか、確認してみましょう。


このようなことから、相関係数が「1」に近いのか、遠いのかによって、データとデータとの間に相関(関係)が強いのか、弱いのを散布図をつかうことで、視覚的に知ることができます。
Facebookページに書いた、Excelの豆知識(Trivia)です。

2月12日
Excel。
QUARTILE.EXC関数
読み方は、クォータイル・ エクスクルーシブで、0%より大きくて100%未満のデータの四分位数を算出します。
2月13日
Excel。
QUARTILE.INC関数
読み方は、クォータイル・ インクルーシブで、0%以上100%以下のデータの四分位数を算出します。
2月14日
Excel。
QUOTIENT関数
読み方は、クオーシャントで、除算した商を算出します。
2月15日
Excel。
RADIANS関数
読み方は、ラジアンで、角度をラジアンに変換する
2月16日
Excel。
RAND関数
読み方は、ランダムで、0以上1未満の範囲で乱数を発生します。
2月17日
Excel。
RANDBETWEEN関数
読み方は、ランダム ビトウィーンで、指定した範囲で整数の乱数を発生します。
2月18日
Excel。
RANK関数
読み方は、ランクで、数値の大小で順位を算出する
大量なデータを読み込んだら、日付は入力されていましたが、曜日は入力されていませんでした。
自分自身で調べて入力するよりも、関数をつかって算出させるほうが楽ですが、データを読み込むたびに、関数を作るのも面倒です。

Sub 曜日()
Dim i As Integer
Dim lastrow As Long
lastrow = Cells(Rows.Count, "a").End(xlUp).Row
For i = 2 To lastrow
Cells(i, "b") = WeekdayName(Weekday(Cells(i, "A")), True)
Next
End Sub
それでは、実行してみましょう。

プログラム文を確認してきます。
最初は、変数宣言ですね。
Dim i As Integer
Dim lastrow As Long
lastrow = Cells(Rows.Count, "a").End(xlUp).Row
このlastrowには、データの最終行番号を代入させることで、この後のFor To Next文の繰り返しに使っています
For i = 2 To lastrow
Cells(i, "b") = WeekdayName(Weekday(Cells(i, "A")), True)
Next
繰り返し文にある
WeekdayName(Weekday(Cells(i, "A")), True)
この行で日付から曜日を表示させているわけです。
「Weekday(Cells(i, "A"))」は、Excelにもある「Weekday関数」と同じで、日曜日を1、月曜日を2と算出してくれる関数です。
ただ、Weekday関数では、曜日に割り振られた番号を算出してくれるだけなので、番号をみて、すぐに何曜日なのかわかりません。
そこで、Excelにはない、「WeekdayName関数」をつかいます。
このWeekdayName関数は、1なら「日」と表示してくれる関数です。
Excelにはない関数もExcel VBAにはいろいろありますので、つかってみるといいかもしれませんね。
DAVERAGE関数
読み方: ディーアベレージ
分類: データベース

DAVERAGE(データべース,フィールド,条件)
条件を満たすレコードの平均を算出します
今回は、SUM関数~SUMSQ関数までをご紹介しております。

SUM関数
読み方: サム
分類: 数学/三角
SUM(数値1,[数値2],…)
数値の合計します
SUMIF関数
読み方: サムイフ
分類: 数学/三角
SUMIF(範囲,検索条件,[合計範囲])
条件付きで数値の合計を行います
SUMIFS関数
読み方: サムイフズ
読み方: サムイフエス
分類: 数学/三角
SUMIFS(合計対象範囲,条件範囲1,条件1,…)
複数の条件付きで数値の合計を行います
SUMPRODUCT関数
読み方: サムプロダクト
分類: 数学/三角
SUMPRODUCT(配列1,[配列2],[配列3],…)
複数の数値の組を掛け合わせて合計を行います
SUMSQ関数
読み方: サムスクウェア
分類: 数学/三角
SUMSQ(数値1,[数値2],…)
数値の2乗の合計を算出します
集計処理で便利なピボットテーブルですが、日付に関して困ることがあります。
次のデータを用意しました。

日付は、お馴染みの「yyyy/m/d」という表示形式です。
では、ピボットテーブルをつかって、日付フィールドを行のレイアウトボックスに設定します。
売上高フィールドは、値のレイアウトボックスに設定しました。
レイアウトボックスは、このようになりました。

ピボットテーブルは、月でグループ化された状態で、表示されています。

そこで、レイアウトボックスから自動的に生成された月フィールドを外します。

ただ、気になるのは、日付の表示形式です。
「月日」の表示形式になっていますが、元データと同じ「yyyy/m/d」に変更しようとすると、出来ないわけです。

フィールドの設定ダイアログボックスが表示されますので、表示形式のボタンをクリックします。
セルの書式設定ダイアログボックスが表示されます。
分類を日付にして、「yyyy/m/d」を選択しても、変更できません。
この原因は、勝手に生成されたグループ化された「月」フィールドなんです。
では、解決方法です。

これで、元データと同じ、表示形式にすることができました。
さて、Microsoft365のExcelには、「Insider版」という、最新機能をお試しでつかえるものがあります。
この問題を、Insider版では、解決させています。

生成された2つのフィールドのチェックマークを外すだけで、元データと同じ表示形式にすることができます。
今後、MicrosoftのExcel365にも反映されていくものと思いますが、現状では、グループ解除をする方法がいいようです。
データを母集団の「一部」と考えて母集団の標準偏差の推定値を算出するならば、「STDEV関数」をつかうことで算出できます。
ただし、条件をつけて算出する場合、データベースを編集する必要があります。
そこで、DSTDEV関数をつかうことで、手早く条件付きで不偏標準偏差を算出することができます。

算出したいのは、クラス「A」の標準偏差です。
C11に設定した数式は、
=DSTDEV(A1:C8,C1,A10:A11)
これで、データを母集団の「一部」と考えて母集団の標準偏差の推定値である「不偏標準偏差」を算出することができました。
A11の条件を変更するだけで、条件に合った不偏標準偏差を算出することができます。
設定した数式を確認しておきましょう。
最初の引数は、「データベース」です。
見出し行も含めた表全体が対象なので、「A1:C8」ですね。
2つ目の引数は、「フィールド」です。
算出したいフィールド(列)を指定しますので、「C1」。
最後の引数は、「条件」です。
「A10:A11」と設定します。
この条件は、事前に用意しておく必要があります。
データベース系の関数はDSUM関数や、DSTDEV関数以外にも色々ありますので、試してみると意外と使えるものがあるかもしれませんね。
DATEVALUE関数
読み方: デイトバリュー
分類: 日付時刻

DATEVALUE(日付文字列)
日付を表す文字列をシリアル値に変換する
表にデータを入力した後に、罫線をひいたり、消したりするのは面倒です。
そこで、データが入力されたら、罫線をひくようにすることはできないものなのでしょうか。
わざわざ、Excel VBAでプログラム文をつくるのも面倒です。
このような場合は、条件付き書式をつかうことで、データが入力されたら罫線をひくことができます。
次の表があります。

範囲選択は、データが入力されるだろうと思われる範囲を選択します。
今回は、A1:C10とします。


「次の数式を満たす場合に値を書式設定」のボックスに、次の数式を設定します。
=$A1<>""
あとは、書式ボタンをクリックして、罫線の設定をします。



なお、この罫線は、条件付き書式をつかってひかれていますので、消したい場合には、条件付き書式を削除する必要があります。
また、設定した数式についてです。
=$A1<>""
1列目に必ず入力されるというルールにしていますので、A1が「””(空白)」でなければ「<>」、罫線をひくという意味の数式です。
列固定の複合参照にすることで、行を対象として、書式設定を設定することができます。
このような場合、書式をこのように設定したいという場合、条件付き書式で出来ないのかを考えてみるのもいいかもしれませんね。